시작하며
64bit 시대를 살고 있는 지금, 개발 - 특히나 웹개발을 하면서 CPU를 신경써가면서 개발하는 경우는 거의 없다. 개발을 도와주는 언어, 컴파일러 등등의 서포트 덕분이기도 하나 CPU의 발전도 개발을 편하게 해주는데 큰 영향을 끼쳤다. 과거에는 CPU의 한계때문에 어떤 문제가 있었는지 간략하게나마 알아보자.
알아보기 앞서 아주 대충 알아보는 CPU의 구조
CPU 는 각 제품마다 아키텍쳐가 워낙 다르고 또한 미친듯이 복잡해서 사실 CPU는 이런 구조다하고 정의 내리기 힘든 면이 있다. 하지만 그래도 공통적인 부분은 대략 아래와 같이 설명할 수 있다.
- 레지스터
- 제어부
- ALU
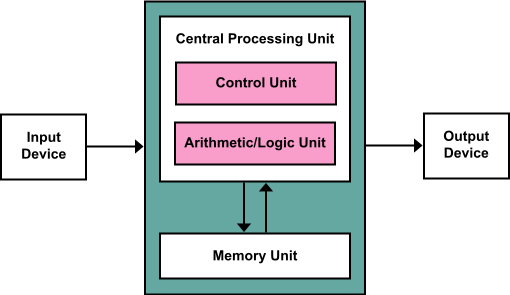
레지스터는 값을 보관하는 기억장치이다. 코딩으로 치면 변수라고 봐도 무방하다. 일반적으로 범용 레지스터와 특수 레지스터로 나뉜다. 일반적으로 레지스터의 사이즈는 CPU의 비트 사이즈와 동일하다.
제어부는 명령어를 해석하고 명령에 해당하는 장치를 동작시킨다.
ALU는 연산을 수행하는 장치이며 산술연산, 논리연산등이 모두 여기서 이루어진다.
xx bit CPU
현재는 64bit CPU가 주류를 이루고 있어 CPU를 구분할 땐 보통 모델명으로 구분하지만, 예전에는 CPU를 구분할 때 가장 먼저 살펴보는 것이 bit 수 였다.
xx bit CPU라고 말할 때 이 xx bit는 CPU가 한 사이클에 처리하는 데이터의 사이즈를 의미한다. 8bit CPU면 한 사이클에 8bit를, 16bit CPU면 한 사이클에 16bit 를 처리한다는 의미다.
사이클은 CPU가 하나의 기계어 명령을 수행하는 주기를 의미한다.(최근의 CPU는 한 사이클에 다수의 명령을 실행한다) 보통 1초당 수행되는 사이클의 횟수를 기준으로 CPU의 속도를 표기하며 1초에 1사이클이면 1Hz 로 표기한다. 현재 CPU는 일반적으로 1.0Ghz 이상의 속도를 가지고 있다.
자료형 문제
CPU의 비트 길이가 모잘랐던 과거에는 프로그램의 동작 속도를 신경써가며 개발해야 했다. 물론 지금도 그렇지만 과거에는 더 중요했고, 비트 수가 모자랄 수록 더욱 신경써서 개발해야 했다.
그럼 CPU 의 비트 길이와 실제 코딩과의 관계는 어떨까. 현재 가장 흔히 사용되는 4바이트 정수형 데이터일 경우를 살펴보자.
16비트 CPU에서 4바이트(=32비트) 데이터 형을 어떻게 읽어야 할까? 한 번에 16bit만 처리할 수 있기 때문에 32비트 데이터를 읽기 위해서는 2번의 사이클이 필요하다. 그럼 32비트 CPU에서 4바이트 데이터형을 읽을 때는? 한 번의 사이클로 데이터를 읽을 수 있다.

즉, CPU의 비트 길이보다 큰 데이터를 처리할 때에는 큰 오버헤드가 걸린다. 비트 길이와 데이터가 맞으면 한 번에 처리가능한 것을 CPU의 비트 길이가 짧다면 2번 이상의 처리 과정이 요구된다. 읽는 것 뿐만 아니다. 덧셈 정도야 상위 16비트, 하위 16비트 나눠서 간단하게 처리가능하다고 해도 곱셈, 나눗셈은 단순히 반반 나눈다고 간단히 처리할 수가 없다.
반대의 경우는?
그럼 반대의 경우 - CPU의 비트 길이보다 데이터 사이즈가 작은 경우는 어떨까? 단순히 생각하면 32bit CPU에서 1바이트인 char 형을 처리하는 것과 4바이트 int 형을 처리하는건 동작속도가 동일할 것으로 추측해볼 수 있다.
다만 여러가지 이유로 인하여(캐시 등등) 실제로는 작은 사이즈를 가진 데이터가 조금 더 빨리 동작할 가능성이 높다.
번외 - float, double
보통 소수를 처리하기 위해서 사용하는 일반적으로 요즘 CPU에서 지원하는 소수 계산 방식은 부동소수점 방식이며, 해당 데이터형의 구조는 아래 그림과 같다.
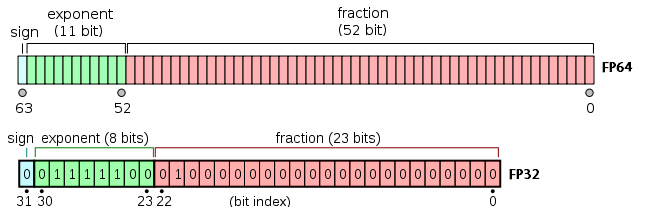
지수 부분과 가수 부분이 나뉘어져있기에 값을 읽는 것 부터 정수 데이터에 비해 CPU 사이클을 잡아먹는다. 사칙연산도 정규화 과정이 추가되는 등 추가적으로 CPU가 해야할 일이 크게 늘어나기 때문에 필연적으로 정수형에 비해 느릴 수 밖에 없다.
메모리 문제
다시 돌아가서, 기본적으로 CPU는 자신의 비트 길이만큼의 데이터를 처리할 수 있다. 메모리 주소 역시 그렇다.
8 bit CPU로 예를 들어보자. 당연히 한 번에 8bit 만 처리할 수 있고, 그렇기에 한 번에 처리할 수 있는 주소의 범위는 8bit, 즉 0 ~ 255 의 주소만 지정할 수 있다. 각 주소 공간의 사이즈는 8비트이므로 8bit CPU가 사용할 수 있는 총 메모리 사이즈는 2048비트, 즉 총 256바이트의 메모리만 사용가능했다.
아무리 8bit CPU라도 이 메모리 사이즈는 너무나 작기에, 주소공간은 16bit 로 처리할 수 있게 설계되었다. 16bit CPU로 넘어와서도 문제는 동일했기에 16bit CPU(인텔 8086의 경우)에서는 20bit 주소 공간을 지원하도록 설계되었다.
다만 CPU의 비트 범위를 초과하여 주소공간을 지원할 수 있게 하다보니 부작용이 발생했다. 가장 큰 문제는 주소공간을 하나의 공간으로 취급할 수 없다는 점이었다. 16bit CPU의 경우 주소 공간은 64kb 이하 영역과 초과 영역으로 나뉘게 된다. 개발자는 이 두가지 영역을 각별히 신경쓰면서 개발을 해야 했으며 조금이라도 어긋나면 큰 문제를 일으키곤 했다. 아래 C 코드를 보자.
#include <stdio.h>
int main() {
char far *p =(char far *)0x55550005;
char far *q =(char far *)0x53332225;
*p = 80;
(*p)++;
printf("%d",*q);
return 0;
}
출처 : https://en.wikipedia.org/wiki/Far_pointer
16비트 인텔 8086 CPU에서 실행했을 시 위 코드의 출력값은 81이다. 서로 다른 주소를 지정한 것처럼 보이지만 16bit를 초과하는 영역의 주소 계산 방식으로 인해 실제로는 두 값 모두 0x55555 주소를 가리키게 되어 발생하는 일이다.
번외 - 사칙연산
코딩을 하면서 사칙연산을 하지 않는 경우는 없다. 가장 원초적인 기능이며 컴퓨터의 근본 그 자체인만큼 사칙연산을 지원하지 않는 CPU는 없다. 사칙연산을 CPU레벨에서 지원하고 수행속도도 매우 빠르지만, 사칙연산별로 수행 속도가 조금씩 다르다.
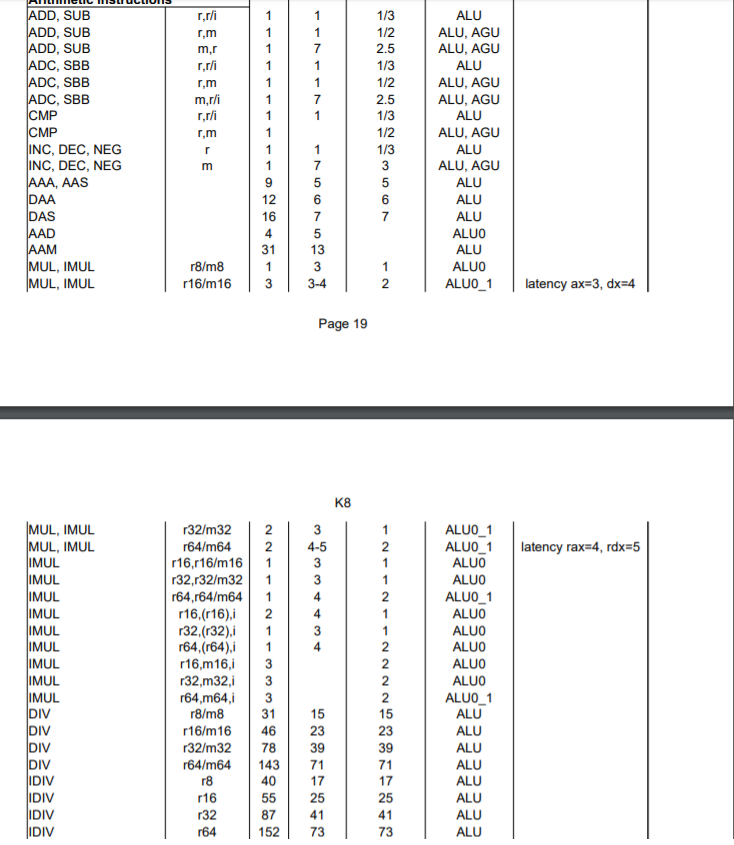
나눗셈의 경우 특히나 느린데, 이는 나눗셈 자체가 복잡하기 때문이다.
마치며
현재는 위에 적은 문제점들은 없으며, CPU의 수행 속도도 CPU를 쥐어짜내는 일을 하지 않는 이상 사실상 신경 쓸 필요가 없을 정도로 빠르다. CPU를 쥐어짜내야 할 일이 생겨도 위처럼 CPU의 동작방식을 이해하여 개선을 시도하는 것 보다는 동작 알고리즘을 개선시키는 편이 훨씬 효과가 좋다. 물론 임베디드 쪽은 여전히 위와 비슷한 문제들을 안고 있긴 하지만…
과거에는 이랬지라는 느낌으로 가볍게 포스트를 써보았다. 이런 문제들을 신경쓰지 않고 개발할 수 있게 해주는 많은 것들에게 감사의 마음을 전한다.