시작하며
이번 포스팅에서는 간단하게 B- 트리, B+ 트리와 스킵리스트에 대해 짤막하게 소개해보고자 한다.
트리란?
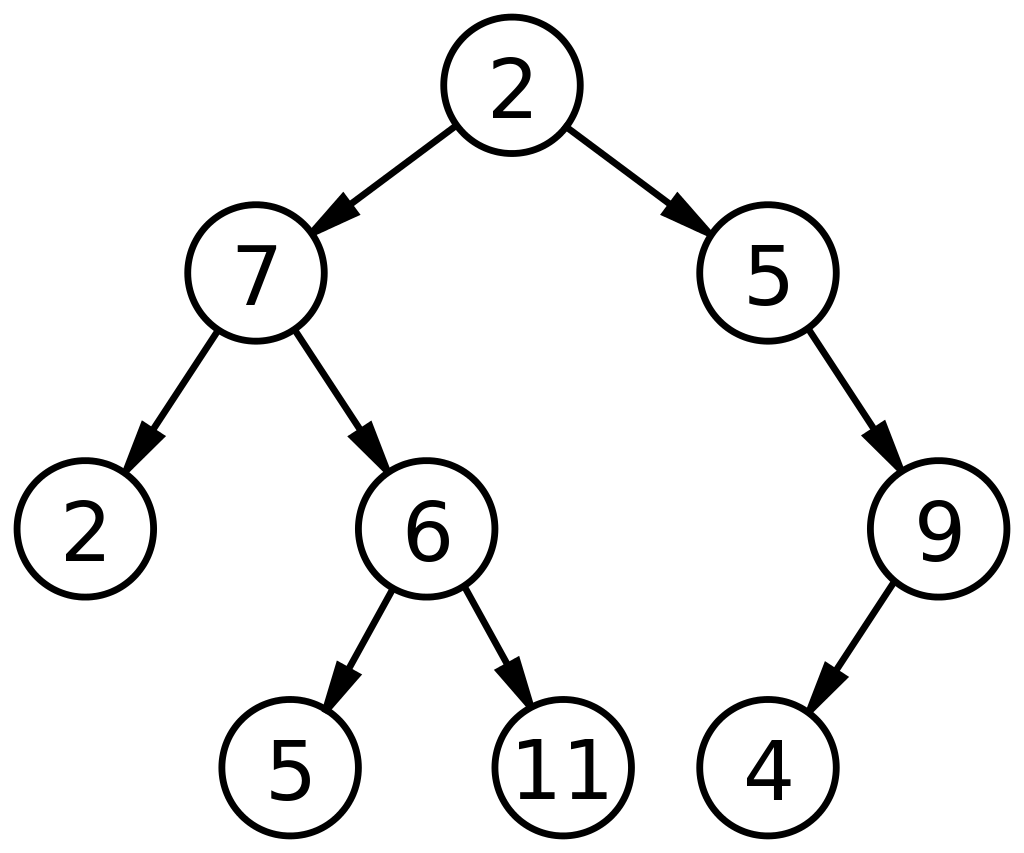
트리란 노드와 간선을 이용하여 데이터를 계층적으로 표현하는 비선형 추상 자료구조 중 하나이다. 노드와 간선으로 이루어져있다는 점에서 알 수 있듯이 본질은 그래프이며, 트리는 그래프의 한 형태이다.
트리, 특히 이진트리를 이용할 경우 원하는 데이터를 찾고자 할 때 크나큰 강점이 있기 때문에 매우 널리 쓰이며 수많은 변형 구조가 있는걸로도 유명하다.
트리는 왜 검색에 유리한가?
간단히 말해 데이터가 삽입될 때부터 애초에 정렬되어 삽입되기 때문이다. 배열이나 링크드리스트도 삽입할 때에 애초에 정렬된 상태로 삽입이 가능하긴 하나, 애초에 고정 사이즈의 제약이 있는 배열이나 추가 인덱스 없이는 반드시 첫노드 부터 순차적으로 탐색을 진행해야 하는 링크드리스트는 애초에 트리와 비교 대상이 될 수가 없다.
B-트리
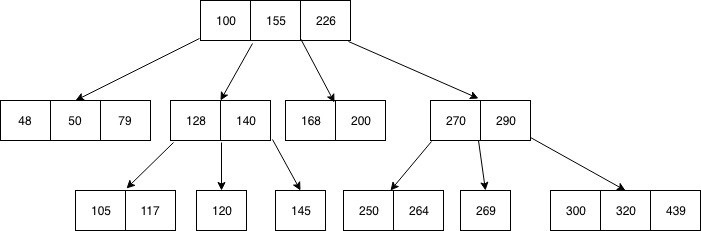
전산학에서 B-트리(B-tree)는 데이터베이스와 파일 시스템에서 널리 사용되는 트리 자료구조의 일종으로, 이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리 구조이다. (출처 : 위키피디아)
구체적인 사항은 인터넷에 검색해보면 하늘의 별만큼 나오니 여기서는 간단히 요점만 소개해본다. 위 그림에서 알 수 있듯이 B- 트리의 가장 큰 특징은 하나의 노드에 다수의 정렬된 값을 저장한다는 것이다. 또한 하나의 자식 노드를 2개 이상 가질 수 있다는 점에서 이진 트리가 아니라고 볼 수 있다. 그렇지만 하나의 데이터가 이진 트리에서의 노드와 비슷한 역할을 수행하기 때문에 실제로는 이진 트리와 유사하게 동작한다.
B+ 트리
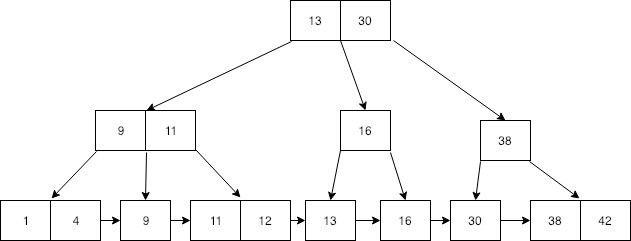
이는 동적이며, 각각의 인덱스 세그먼트 (보통 블록 또는 노드라고 불리는) 내에 최대와 최소범위의 키의 개수를 가지는 다계층 인덱스(multilevel index)로 구성된다.
B트리와 대조적으로 B+트리는, 모든 레코드들이 트리의 가장 하위 레벨에 정렬되어있다. 오직 키들만이 내부 블록에 저장된다. (출처 : 위키피디아)
B+ 트리는 B-트리의 단점을 보완한 트리인데 가장 큰 차이점은 모든 데이터는 리프 노드에만 존재하며 그 리프 노드들은 링크드 리스트로 연결되어 있다는 것이다. 리프 노드보다 상위에 있는 노드들은 오직 인덱스만 저장된다.
SkipList
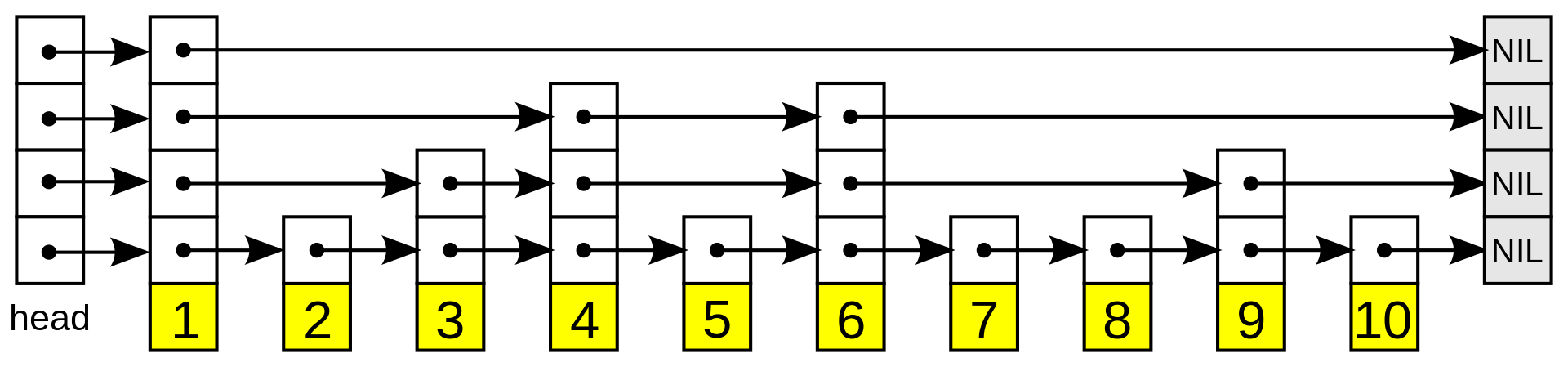
스킵리스트는 검색, 삽입, 삭제에 대해 시간복잡도 O(log n)를 가지는 정렬된 데이터를 가지는 확률적 자료구조이다. (출처 : 위키피디아)
스킵리스트는 리스트라는 이름에서 알 수 있듯이 링크드 리스트의 일종이다. 1989년에 발명되었으나 본격적으로 사용된건 2000년대 이후로 비교적 근래의 자료구조라고 할 수 있다.
트리의 경우 삽입 및 삭제 시 노드의 위치에 따라 오버헤드가 발생할 수 있다. RDB같은 경우는 트랜잭션까지 같이 맞물리게 되므로 더욱 오버헤드가 커진다.
반면 링크드 리스트의 경우는 원하는 노드까지 접근하는 시간은 오래 걸리나 삽입 삭제 과정은 지극히 단순하다. 이 장점을 십분 활용하면서 탐색 시간을 줄여보고자 하는 아이디어에서 나온 것이 스킵리스트다.
DB를 사용하는 개발에서는 삽입은 어쩔 수 없다고 치더라도 삭제는 가급적 지양하는 경우가 많은데, 개발하다 보면 삽입 삭제를 매우 많이 반복해야 하는 케이스가 있으며 이럴 때 유용한 것이 스킵리스트이다.
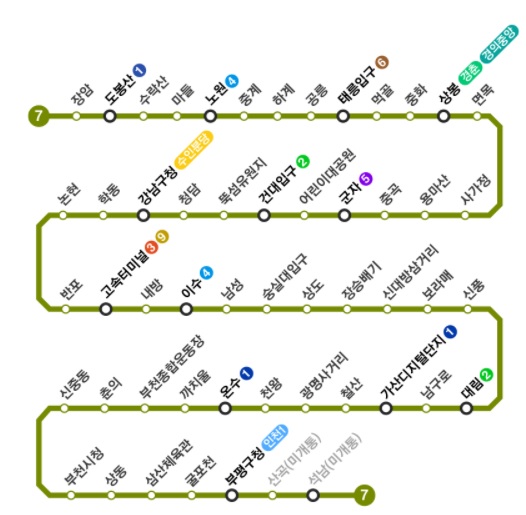
링크드 리스트를 설명할 때엔 열차 노선만한게 없는데 스킵리스트도 마찬가지다. 둘 다 선형 리스트이고, 하나의 역이 하나의 노드와 매칭이 되기 때문이다. 다만 현실에서는 역 사이를 이동하는 시간이 제각기 다르지만 여기는 역 사이를 이동하는 시간은 모두 0, 역에서 정차하는 시간은 1 이라고 가정하자.
위 7호선에서 장암역에서 가산디털단지까지 갈려면 역을 37개 역을 거쳐야 갈 수 있다. 즉, 총 이동 시간이 37이 걸린다.
이것을 단축할려면 어떻게 해야 할까? 답은 아주 간단하다. 급행 노선을 추가하면 된다.(물론 현실에서는 많은 이유로 불가능하지만)
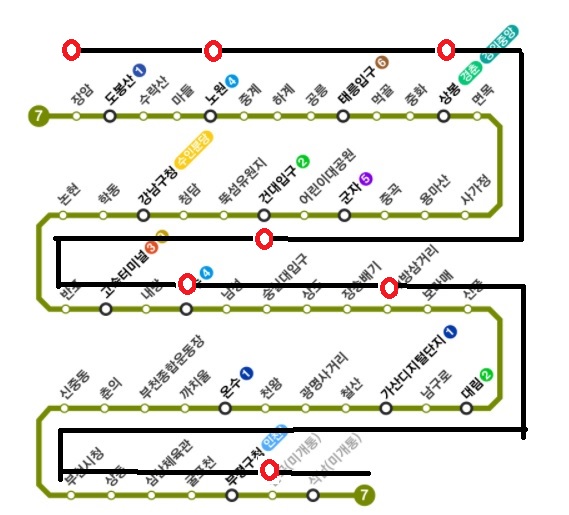
위처럼 급행 노선이 추가되었다고 가정한다면 장암에서 가산디지털단지 까지는 10개 역만 거치면 된다. 탐색 시간이 1/3 이하로 줄어든 것이다.
스킵리스트의 원리는 위의 급행노선처럼 빨리 갈 수 있는 또 다른 루트를 만드는 것이다. 현실에서야 급행노선 하나 추가하기도 벅차지만 컴퓨터 안에서야 메모리가 허락하는대로 급행 노선을 추가할 수 있다. 스킵리스트에서는 이 급행 노선을 Level N 식으로 구분하게 된다.
물론 실제로는 몇몇 문제들 때문에 무한히 추가할 순 없으며 보통 최대 레벨은 32이하로 설정한다. 필요 이상으로 레벨이 많을 경우 삽입 삭제에 그만큼 손해가 발생하게 된다.
트리 vs스킵리스트
탐색도 빠르고 삽입,삭제도 빠르면(게다가 쉽다!) 스킵리스트만 써도 충분하지 않을까 싶지만 현실은 그렇지는 않다. 여전히 트리가 더 많이 사용되고 있으며 그 이유는
- 트리는 최악의 경우에도 O(log n)의 탐색시간을 보장하지만 스킵리스트는 최악의 경우에는 O(n) 이 된다.
- 평균적인 탐색 시간은 트리가 더 빠르다.
- 스킵리스트는 레벨이 늘어날 수록 추가 메모리가 필요.
등이 되겠다.